

Retomamos nuestra serie de artículos sobre IA. Ya hemos avanzado con las características de la inteligencia artificial, también vimos cómo funciona el modelo de procesamiento de lenguaje natural, y luego el aprendizaje automático. Esta vez, vamos con un tema que os interesa mucho, y que cada día nos sorprende más y más, tanto por el “realismo” de sus resultados como por la controversia que genera. Hablo de la generación automática de imágenes: esa «habilidad» asombrosa de la IA para imaginar, pintar y producir, a partir de una simple línea de texto, una obra visual. Es básicamente el sueño de todo desarrollador visualmente torpe… como yo cuando intentaba hacer interfaces con Qt a pulso en 2003.
Lo cierto es que, desde que surgieron herramientas como DALL·E, Stable Diffusion o Midjourney, hemos sido testigos de un nuevo salto evolutivo en la interacción humano-máquina. La inteligencia artificial ya no es solo cálculo estadístico ni clasificación: ahora también puede «soñar». Y lo hace con una nitidez maravillosa.
En lo personal, creo que estas tecnologías representan uno de los avances más potentes (y sí, también más polémicos) en lo que se refiere a la creación de contenido digital. Todo esto se ha logrado gracias a una combinación de arquitectura neuronal, poder de cómputo y datasets masivos que pondrían celoso hasta al mismísimo Alan Turing. Pero antes de lanzarnos a visualizar renders de ciudades cyberpunk, debemos entender bien qué son los modelos generativos de imágenes, cómo funcionan los modelos generativos de imágenes y por qué han capturado la atención de ingenieros, artistas y empresas de marketing por igual.
En este artículo analizaremos desde una perspectiva técnica, cómo funcionan los modelos generativos de imágenes, explicando sus arquitecturas base (GANs, Diffusion, Transformers), cómo interactúan con el lenguaje mediante sistemas como CLIP, y cómo herramientas como Midjourney logran ese grado casi mágico de precisión estética. También repasaremos casos de uso reales en prototipado, ingeniería y diseño gráfico, además de entrar a fondo en sus implicaciones éticas y legales. Y sí, también hablaremos de eso que os carcome por dentro: cómo saber si una IA está plagiando, inspirándose o simplemente imitando mejor que los humanos.
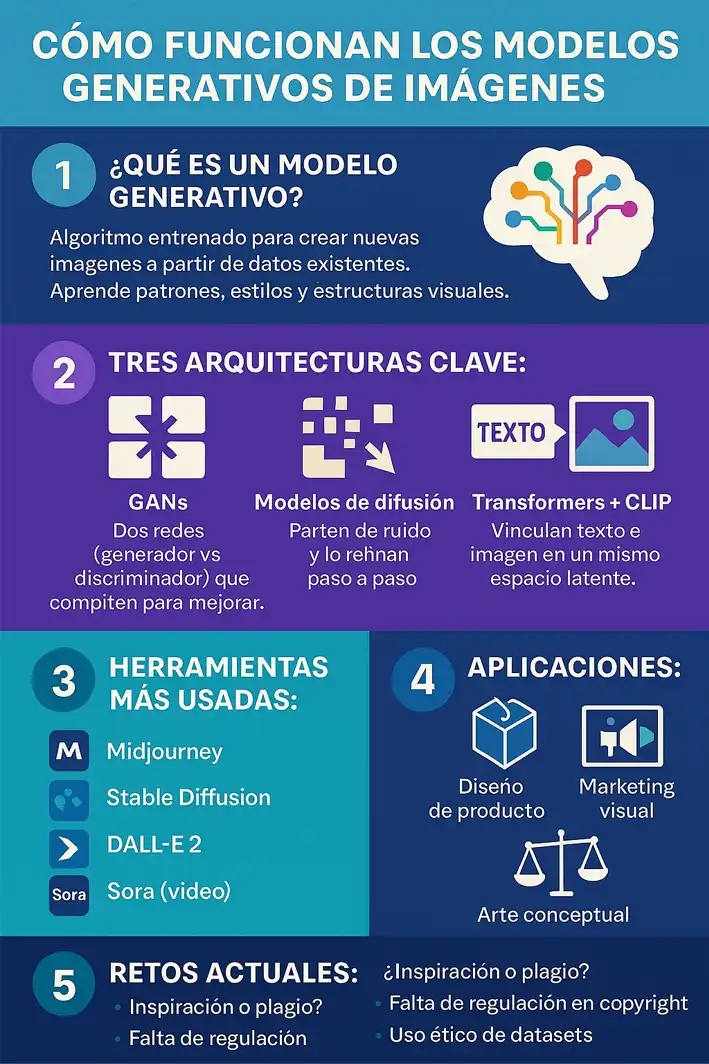
Qué son los modelos generativos de imágenes

Un modelo generativo es un algoritmo entrenado para aprender la distribución de los datos de entrada (imágenes, texto, audio, etc.) y luego generar nuevos ejemplos que podrían haber pertenecido a esa distribución. Dicho de otro modo: intenta imitar la «firma estadística» de un conjunto de datos. En el caso de los modelos generativos de imágenes, esta distribución está hecha a base de millones (a veces billones) de imágenes etiquetadas con texto.
Podemos dividir los modelos generativos por IA en tres categorías:
- GANs (Redes Generativas Antagónicas): un modelo se dedica a crear imágenes (generador), otro a detectar si son falsas o reales (discriminador), y ambos se enfrentan en una especie de entrenamiento Jedi-Sith hasta que el generador es capaz de engañar al discriminador con imágenes creíbles (Goodfellow et al., 2014).
- Modelos de difusión: en lugar de crear directamente desde el vacío, comienzan con una imagen llena de ruido y van «limpiándola» iterativamente para revelar una imagen coherente. Esto es más estable, aunque requiere más pasos de inferencia.
- Transformers + Embeddings: aquí es donde entra CLIP, el modelo de OpenAI que mapea texto e imagen al mismo espacio latente. Esencialmente, traduce palabras e imágenes a una misma lengua matemática (Radford et al., 2021).
Ahora bien, cada arquitectura tiene sus ventajas; las GANs fueron las pioneras en generación visual de calidad, pero los modelos de difusión son hoy el estándar por su mayor control y fidelidad al prompt. Combinados con embeddings textuales como los de CLIP, dan vida a los modernos modelos de texto a imagen, como DALL·E 2, Stable Diffusion o GPT‑4o.
Cómo funcionan los modelos generativos de imágenes
Si alguna vez te has preguntado cómo demonios una IA puede transformar una frase como «Un dragón mecánico flotando sobre un desierto de circuitos» en una imagen que parece salida de la mente de H.R. Giger después de una noche con Red Bull, la respuesta está en la arquitectura matemática de las tres grandes tipos de redes qye ya te expliqué: GANs, Modelos de Difusión y Transformers con embeddings multimodales.
Es decir, el modelo no «dibuja». El modelo aprende a modelar una probabilidad: la de que cierta configuración de píxeles (una imagen) sea coherente con un concepto dado (tu prompt). Es como tener una tabla hash de probabilidades entre descripciones y composiciones visuales, pero en lugar de llaves y valores, tienes vectores de cientos de dimensiones que representan significados abstractos.
1. Etapa de entrada: codificación del texto
Todo empieza con tu prompt. No es magia, es NLP. Ese texto pasa por un encoder (tipo BERT, T5 o CLIP-Text), que lo traduce a un vector de embeddings semánticos. Este vector es el ADN del significado de tu frase. No contiene imágenes aún, pero sí la esencia conceptual que va a condicionar el resto del proceso.
En modelos como DALL·E 2 o GPT‑4o, esta codificación se hace en un espacio latente entrenado para relacionar directamente texto con imágenes, gracias a la arquitectura CLIP (Contrastive Language-Image Pretraining).
2. Representación intermedia: el espacio latente
Aquí es donde se separan los modelos buenos de los que parecen generadores de memes de los 2000. En lugar de trabajar directamente en espacio de píxeles (lo cual sería brutalmente costoso), los modelos como Stable Diffusion usan lo que se llama un espacio latente comprimido, donde una imagen de 512×512 se representa como una matriz mucho más pequeña, típicamente de 64×64×4 dimensiones.
¿Por qué? Porque es más eficiente, y porque en ese espacio los patrones visuales son más fáciles de manipular matemáticamente. Es como trabajar con el bytecode de una imagen, no con el binario crudo.
3. Generación visual: modelos de difusión
Ahora viene el proceso más hermoso y contraintuitivo. Los modelos de difusión (el estado del arte actual) no generan una imagen de cero. Lo que hacen es comenzar con ruido puro, y poco a poco, como quien revela una foto en una cámara oscura, van «limpiando» el ruido mediante múltiples pasos de inferencia.
En cada paso, el modelo predice cómo debería lucir una versión menos ruidosa de esa imagen, condicionado por el embedding del texto. Es decir: Imagen_rn+1 = Imagen_rn – Ruido_predicho_por_la_red(Imagen_rn, Texto)
Este proceso iterativo puede durar entre 25 y 1000 pasos, dependiendo de la configuración y del modelo. Por eso estas IA tardan varios segundos en generar imágenes: no es una generación directa, sino un refinamiento continuo.
Este enfoque, introducido en libros de inteligencia artificial y papers como DDPM (Ho et al., 2020), y refinado por Latent Diffusion Models (Rombach et al., 2022), permite lograr imágenes de altísima calidad con mucho más control sobre el resultado.
4. Atención cruzada: el pegamento entre texto e imagen
Durante el proceso de denoising, se aplica algo que es pura alquimia digital: cross-attention. Esta técnica permite que el modelo enfoque partes específicas del texto mientras decide cómo limpiar el ruido.
¿Recuerdas cuando decías «un dragón mecánico flotando sobre un desierto de circuitos«? Pues esta atención cruzada permite que la red sepa que «dragón» debe ser un objeto central, «mecánico» es una textura o material, y «desierto de circuitos» es un fondo visual coherente. Y todo esto se ajusta dinámicamente en cada capa del modelo de difusión, que suele estar basado en un U-Net con skip connections.
5. Decodificación: de latente a píxeles
Cuando se ha terminado el proceso de denoising, tienes una imagen latente refinada. El siguiente paso es pasarla por un decodificador (decoder), usualmente un autoencoder convolucional entrenado para revertir la compresión inicial.
Este decoder transforma la representación latente en una imagen de verdad, en 512×512, 768×768 o la resolución que permita el modelo.
Cómo funciona Midjourney y por qué mola tanto
¿Cómo funciona Midjourney? Spoiler: no lo sabemos del todo porque es código cerrado, pero hay bastantes pistas. Midjourney está construido sobre el paradigma de diffusion models, como Stable Diffusion, pero con entrenamiento adicional y ajustes muy afinados para generar imágenes estilizadas, creativas y llamativas.
Los ingenieros detrás de Midjourney han sido muy hábiles en dos cosas:
- Afinar los pesos del modelo para favorecer outputs artísticos
- Curar datasets con imágenes más estéticas
- Aplicar probablemente retroalimentación humana (RLHF) para alinear los resultados con el gusto visual del usuario final.
Una de las claves del éxito de Midjourney es su comunidad y su experiencia interactiva en Discord, donde puedes generar imágenes mediante comandos, observar resultados de otros usuarios y refinar tus propias creaciones. La interfaz de usuario importa, y eso lo han entendido mejor que muchos otros proyectos. Técnicamente, sigue siendo un modelo de texto a imagen, pero con una afinación muy centrada en la creatividad.
Aplicaciones reales: diseño, prototipado y más allá
Aquí es donde la cosa se pone interesante para ingenieros, diseñadores y creativos digitales. Veamos algunas aplicaciones concretas de los modelos generativos por IA en el mundo real:
- Prototipado rápido de piezas mecánicas: imagina que describes una pieza de montaje industrial con ciertos ejes y ángulos, y el modelo te devuelve un render visual que puedes usar para validar conceptos.
- Diseño gráfico y marketing: desde portadas de libros hasta conceptos visuales para campañas publicitarias. Las IA creativas están ya en las agencias.
- Arte conceptual para videojuegos y películas: entornos alienígenas, personajes fantásticos, moodboards para escenas completas.
- Arquitectura e interiorismo: generación de espacios con estilos definidos, iluminación virtual o propuestas de remodelación.
Estas herramientas reducen tiempos, inspiran ideas y permiten múltiples iteraciones a coste cero. Y eso, en cualquier industria, es un Game Changer.
Imagen a imagen: edición creativa guiada por IA

No todo en este campo se reduce a generar una imagen desde cero. A veces, lo que necesitas es modificar, reinterpretar o mejorar una imagen existente. Aquí entra el concepto de imagen a imagen (img2img), que permite transformar una entrada visual usando también texto como guía.
¿La técnica? Muy parecida a la que vimos antes con modelos de difusión, solo que esta vez en vez de partir de ruido puro, el modelo parte de una imagen existente y le añade un poco de ruido. Luego, el proceso de denoising (limpieza de ese ruido) está guiado por tu prompt textual. Es lo que hacen sistemas como Stable Diffusion en modo img2img, o herramientas como ControlNet (Zhang et al., 2023), que permite controlar con precisión el resultado final mediante máscaras, poses humanas, bordes o mapas de profundidad.
Esto permite cosas como:
- Reilustrar una escena manteniendo la composición original
- Transformar un diseño técnico en un render artístico
- Hacer outpainting (extender los bordes de la imagen).
- Aplicar un estilo visual a una fotografía, al estilo style transfer 2.0.
A nivel técnico, la idea clave es que el modelo no necesita ser reentrenado desde cero para cada tarea. Gracias a arquitecturas modulares, como ControlNet, simplemente se le añaden capas adicionales que condicionan el proceso de generación en tiempo de inferencia. Eficiencia, flexibilidad y control: la trinidad del diseño generativo moderno.
De texto a video e imagen a video: IA que anima tus ideas
Y ahora entramos en terreno más reciente, pero no menos fascinante. Si las imágenes generadas por IA ya nos dejan con la mandíbula colgando, los modelos de generación de video son el siguiente nivel de locura tecnológica.
Hablamos de modelos como Sora (OpenAI, 2024), Imagen Video (Google, 2022), o Stable Video Diffusion (Stability AI, 2023), que amplían el paradigma de texto a imagen al de texto a video o imagen a video. ¿La clave? Añadir una dimensión temporal al modelo: no basta con generar frames, hay que asegurar coherencia entre fotogramas, continuidad de movimiento y persistencia visual.
Estos modelos suelen funcionar en cascada:
- Primero generan un video en baja resolución y pocos FPS
- Luego, lo refinan mediante modelos adicionales que aplican superresolución y suavizado temporal.
Lo realmente geek aquí es que los modelos modernos no generan píxeles directamente: comprimen los videos en espacios latentes y operan con bloques espacio-temporales llamados patches. Es decir, trabajan con mini-volúmenes que representan segmentos del video en espacio y tiempo. ¿Te suena a Transformers? ¡Correcto! Algunos modelos, como Sora, usan transformers como difusores, lo que permite entender relaciones complejas a lo largo de múltiples dimensiones.
¿Qué se hace con esta tecnología?
- Videos de producto generados a partir de descripciones
- Simulación de movimientos en arquitectura y diseño
- Presentaciones animadas con input mínimo.
Por ahora, los resultados están limitados en duración (unos segundos) y resolución, pero el salto cualitativo es innegable. La IA ya no solo imagina imágenes: empieza a soñar en movimiento.
¿Qué pasa con los derechos, la ética y el copyright?
Llegados a este punto, si eres abogado, artista o simplemente alguien con sentido común, te habrás cuestionado lo siguiente: ¿Quién es el dueño de lo que genera la IA? ¿Y si está usando mi estilo, mi cara o mi dataset sin permiso?
Los debates éticos sobre IA generativa son tan calientes como los foros de kernel en Reddit. Hay demandas abiertas (Getty vs. Stability AI), marcos legales aún en desarrollo, y cada vez más herramientas de trazabilidad como C2PA (Content Authenticity Initiative) que intentan marcar qué imagen fue generada por IA, cómo, cuándo y con qué base.
Pero más allá del tema legal, hay también un asunto filosófico: si una IA crea algo con base en 5 mil millones de imágenes extraídas de la web, ¿no está simplemente «mezclando» como haría un humano? ¿Dónde empieza la inspiración y termina la copia?
Estas preguntas no tienen respuesta clara todavía, pero sí podemos decir que los avances técnicos deben ir acompañados de marcos éticos sólidos. Y eso es algo que, como comunidad técnica, no podemos delegar solo en abogados. La gobernanza del código, el dataset y el uso es tarea de todos.
Un futuro no tan lejano: IA creativa como asistente universal
Los modelos generativos están ganando terreno no solo en diseño o arte, sino también en campos más “formales” como la educación, donde ya se han probado como asistentes visuales, generadores de material gráfico o incluso como tutores automáticos que explican conceptos con imágenes personalizadas. Aquí entra uno de los grandes debates abiertos, analizar las ventajas y desventajas de la IA en la educación.
Por un lado, tenemos acceso inmediato a material visual adaptado a cada estudiante, mejora de la comprensión espacial, apoyo a la diversidad de estilos de aprendizaje. Pero por otro, existe el riesgo de sobredependencia, pérdida de pensamiento crítico o sesgos en el contenido si los datasets de entrenamiento no están bien curados. El equilibrio aquí es fundamental, y debe ser tratado con tanto rigor como entusiasmo.
Mientras tanto, en otros sectores, ya vemos avances con herramientas más prácticas como los plugins de traducción con IA, integrados en editores de texto, navegadores o sistemas CMS. Estos complementos además de traducir, sino que adaptan el tono, el contexto y hasta la estructura sintáctica de forma semánticamente coherente con el contenido original. Esto ha transformado la manera en que se localiza contenido visual generado por IA en campañas globales.
Si lo unes todo /texto, imagen, traducción y animación( tienes un sistema multimodal que puede generar desde una infografía educativa hasta un spot publicitario en 5 idiomas. Todo, literalmente, desde un prompt.
¿Hacia dónde vamos?
El futuro inmediato pasa por la optimización y democratización de estos modelos. Reducción de consumo computacional, mayor control por parte del usuario, integración nativa en navegadores, IDEs, sistemas operativos.
El sueño de muchos (me incluyo) es una IA creativa que colabore directamente en proyectos de código, diseño, arquitectura o educación, sin que tengas que cambiar de ventana o formato. Ya hay avances hacia ese horizonte: modelos como GPT‑4o han empezado a combinar texto, visión y lógica de manera coherente. Y eso es solo el principio.
Ya que sabes cómo funcionan los modelos generativos de imágenes, debes saber que no son solo “juguetes”. Son herramientas de transformación, y como tales, debemos aprender a usarlas, y decidir hasta dónde las dejamos llegar.
Referencias:
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial networks. arXiv preprint arXiv:1406.2661. https://doi.org/10.48550/arXiv.1406.2661
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239. https://doi.org/10.48550/arXiv.2006.11239
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10684–10695. https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020. https://doi.org/10.48550/arXiv.2103.00020
- OpenAI. (2024). Video generation models as world simulators. https://openai.com/index/video-generation-models-as-world-simulators/
- Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D. P., Poole, B., Norouzi, M., Fleet, D. J., & Salimans, T. (2022). Imagen Video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303. https://doi.org/10.48550/arXiv.2210.02303
- Stability AI. (2023). Stable Video Diffusion: Image-to-Video. Hugging Face. https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
")






